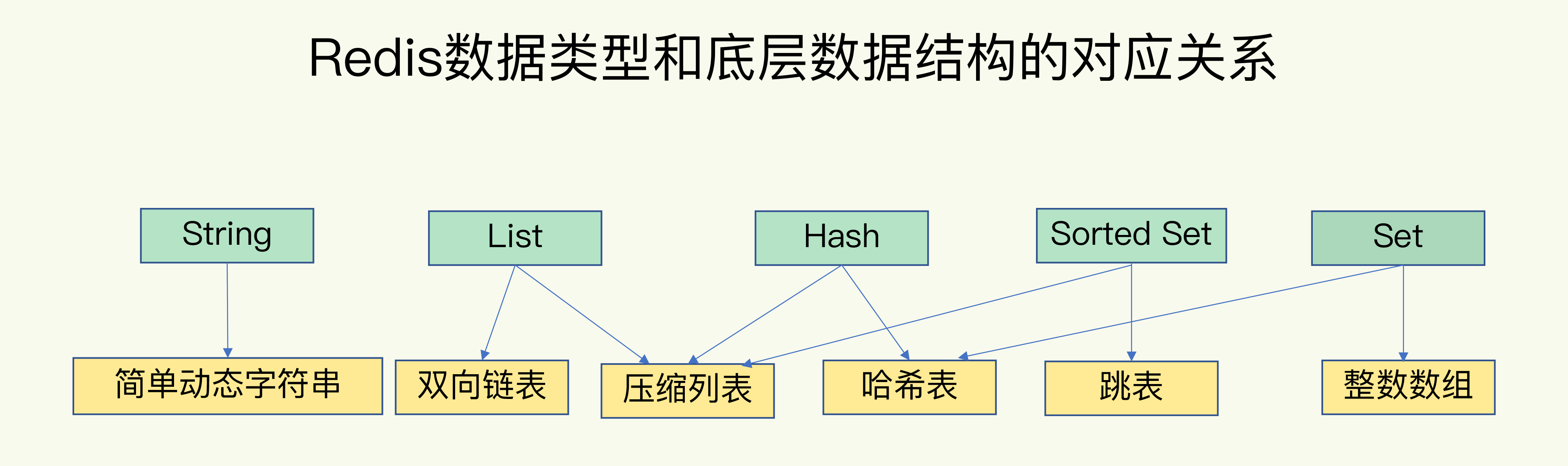
REDIS 数据类型
数据结构
简单来说,底层数据结构一种6种.
- 动态字符串
- 双向链表
- 压缩列表
- 哈希表
- 跳表
- 整数数组
数据类型
- string 字符串
- list 列表
- hash 字典
- sorted set 有序集合
- set 集合
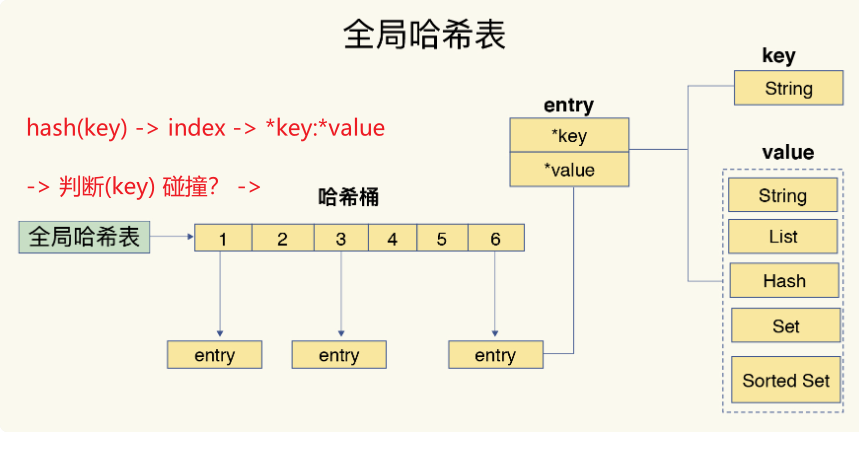
键和值 用什么结构组织?
REDIS 使用了一个哈希表来保存键值对.
一个哈希表,其实就是一个数组。而数组的每一个元素,称为一个哈希桶。
哈希桶内保存了键值对数据。其中,哈希桶内保存的键值对数据,并不是本身,而是具体值的指针。
这个是REDIS的全局哈希表。 哈希时,操作复杂度是O(1)。
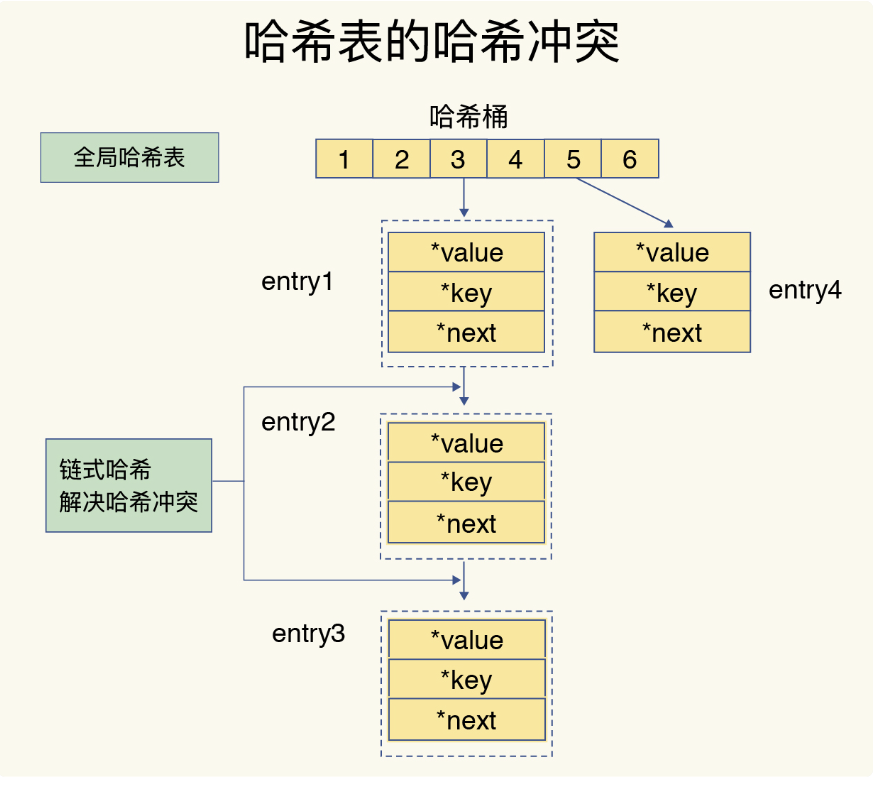
解决哈希冲突
REDIS 解决哈希冲突的方式,就是链式哈希。
链式哈希,就是同一个哈希桶中,多个元素,用一个列表来保存。
元素之间,用指针链接。
引入问题:
就是链式哈希存储过多的entry,导致效率降低。
解决问题:
REHASH
REHASH
其实就是扩容, 增加哈希桶的数量。从而让entry存储的更加分散。
存在同一个哈希桶中的过多的元素, 也可以分散开来。
REDIS为了增加REHASH的效率,其实使用了2个全局哈希表。
- 使用哈希表1,当数据足够多时,申请哈希表2的空间是1的2倍。
- 把哈希表1中的数据,映射到哈希表2中
- 使用哈希表2,释放哈希表1
- 下次往复操作。
上面的操作中, 步骤2会拷贝大量数据,从到造成REDIS线程阻塞,为了避免这个问题,采用了渐进式的REHASH
渐进式操作,其实就是再处理请求时,每次处理请求的同时,顺带着完成一次索引位置(哈希桶)的copy(表1映射到表2)。
当哈希表从头copy,到表尾时,也就完成了copy.
ps. 同时可以同时操作哈希表1和哈希表2. 避免新数据未拷贝,类似数据库迁移,数据写入存2份。
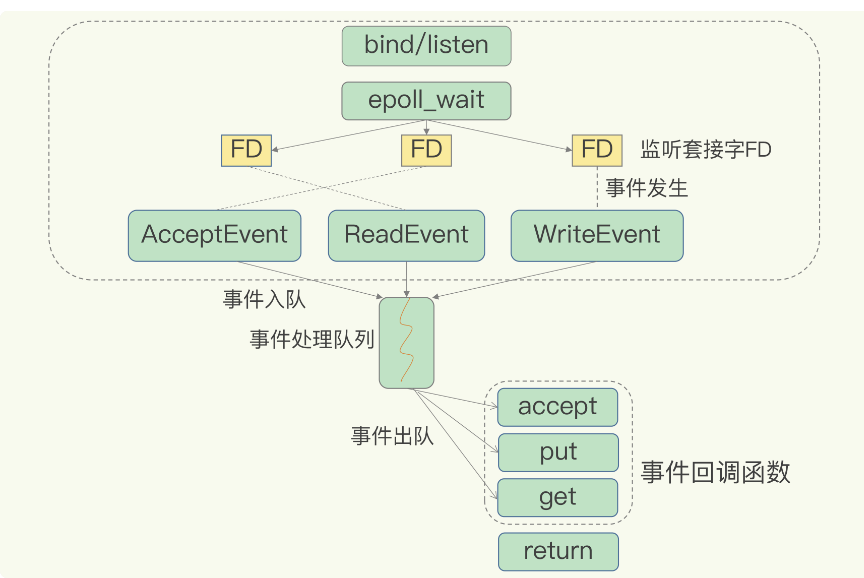
Redis基于单线程,为什么快?
首先强调, 多线程不一定快, 因为cpu频繁的线程间上下文切换,会增加性能消耗.
其次, 我们常说的Redis的单线程, 是指处理网络请求的模块,是一个IO多路复用的单线程.
即保证处理效率,又省去并发的安全性.
其他模块仍然使用了多个线程.
好了,继续说, Redis为什么快?
- Redis大部分操作,在内存中完成, 内存的读写速度很快,再加上Redis采用的高效的数据结构,保证了效率.
- 第二点就是,单线程采用了 多路复用机制.
什么是多路复用?
IO多路复用,就是我们常说的select/epoll机制.
该机制允许内核中,同时存在多个监听套接字和连接套接字
内核会一直监听这些套接字上的连接请求或数据请求。
一旦请求到达,就会交给Redis线程处理,这就实现了一个Redis线程处理多个IO流的效果。
为了在请求达到后 能及时通知Redis线程, select/epoll提供了基于事件的回调机制,
只要检测到FD上有请求达到,就会触发相应的事件。
这些事件会放进一个队列,Redis线程对这个队列不断进行处理。
Redis处理事件时候,会调用相应的处理函数,就实现了基于事件的回调。
Redis无需一直轮询是否有请求,避免了CPU的浪费。